Data protection hasn’t changed much in a long time. Sure, there are slews of product announcements and incessant declarations of the “next big thing”, but really, how much have market shares really changed over the past decade? You’ve got to wonder if new technology is fundamentally improving how data is protected or is simply turning the crank to the next model year. Are customers locked into the incremental changes proffered by traditional backup vendors or is there a better way?
Not going to take it anymore
The major force driving change in the industry has little to do with technology. People have started to challenge the notion that they, not the computing system, should be responsible for ensuring the integrity of their data. If they want a prior version of their data, why can’t the system simply provide it? In essence, customers want to rely on a computing system that just works. The Howard Beale anchorman in the movie Network personifies the anxiety that burdens customers explicitly managing backups, recoveries, and disaster recovery. Now don’t get me wrong; it is critical to minimize risk and manage expectations. But the focus should be on delivering data protection solutions that can simply be ignored.
Are you just happy to see me?
The personal computer user is prone to ask “how hard can it be to copy data?” Ignoring the fact that many such users lose data on a regular basis because they have failed to protect their data at all, the IT professional is well aware of the intricacies of application consistency, the constraints of backup windows, the demands of service levels and scale, and the efficiencies demanded by affordability. You can be sure that application users that have recovered lost or corrupted data are relieved. Mae West, posing as a backup administrator, might have said “Is that a LUN in your pocket or are you just happy to see me?”
In the beginning
Knowing where the industry has been is a good step in knowing where the industry is going. When the mainframe was young, application developers carried paper tape or punch cards. Magnetic tape was used to store application data as well as a media to copy it to. Over time, as magnetic disk became affordable for primary data, the economics of magnetic tape remained compelling as a backup media. Data protection was incorporated into the operating system through backup/recovery facilities, as well as through 3rd party products.
As microprocessors led computing mainstream, non-mainframe computing systems gained prominence and tape became relegated to secondary storage. Native, open source, and commercial backup and recovery utilities stored backup and archive copies on tape media and leveraged its portability to implement disaster recovery plans. Data compression increased the effective capacity of tape media and complemented its power consumption efficiency.
All quiet on the western front
Backup to tape became the dominant methodology for protecting application data due to its affordability and portability. Tape was used as the backup media for application and server utilities, storage system tools, and backup applications.
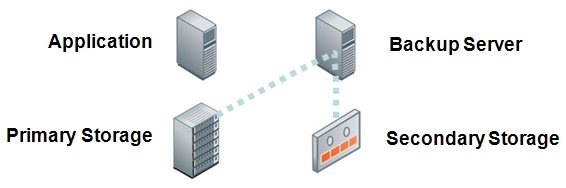
Backup Server copies data from primary disk storage to tape media
Customers like the certainty of knowing where their backup copies are and physical tapes are comforting in this respect. However, the sequential access nature of the media and indirect visibility into what’s on each tape led to difficulties satisfying recovery time objectives. Like the soldier who fights battles that seem to have little overall significance, the backup administrator slogs through a routine, hoping the company’s valuable data is really protected.
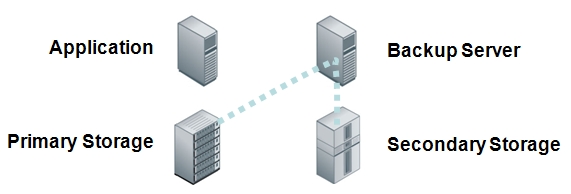
- Backup Server copies data to a Virtual Tape Library
Uncomfortable with problematic recovery from tape, customers have been evolving their practices to a backup to disk model. Backup to disk and then to tape was one model designed to offset the higher cost of disk media but can increase the uncertainty of what’s on tape. Another was to use virtual tape libraries to gain the direct access benefits of disk while minimizing changes in their current tape-based backup practices. Both of these techniques helped improve recovery time but still required the backup administrator to acquire, use, and maintain a separate backup server to copy the data to the backup media.
Snap out of it!
Space-efficient snapshots offered an alternative data protection solution for some file servers. Rather than use separate media to store copies of data, the primary storage system itself would be used to maintain multiple versions of the data by only saving changes to the data. As long as the storage system was intact, restoration of prior versions was rapid and easy. Versions could also be replicated between two storage systems to protect the data should one of the file servers become inaccessible.
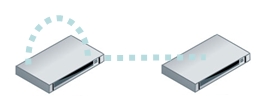
Point in Time copies on disk storage are replicated to other disks
This procedure works, is fast, and is space efficient for data on these file servers but has challenges in terms of management and scale. Snapshot based approaches manage versions of snapshots; they lack the ability to manage data protection at the file level. This limitation arises because the customer’s data protection policies may not match the storage system policies. Snapshot based approaches are also constrained by the scope of each storage system so scaling to protect all the data in a company (e.g., laptops) in a uniform and centralized (labor-efficient) manner is problematic at best.
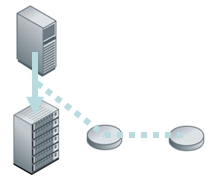
Writes are captured and replicated for protection
Continuous Data Protection (both “near CDP” solutions which take frequent snapshots and “true CDP” solutions which continuously capture writes) is also being used to eliminate the backup window thereby ensuring large volumes of data can be protected. However, the expense and maturity of CDP needs to be balanced with the value of “keeping everything”.
An offer he can’t refuse
Data deduplication fundamentally changed the affordability of using disk as a backup media. The effective cost of storing data declined because duplicate data need only be stored once. Coupled with the ability to rapidly access individual objects, the advantages of backing up data to deduplicated storage are overwhelmingly compelling. Originally, the choice of whether to deduplicate data at the source or target was a decision point but more recent offerings offer both approaches so customers need not compromise on technology. However, simply using deduplicated storage as a backup target does not remove the complexity of configuring and supporting a data protection solution that spans independent software and hardware products. Is it really necessary that additional backup servers be installed to support business growth? Is it too much to ask for a turnkey solution that can address the needs of a large enterprise?
The stuff that dreams are made of
Transformation from a Backup Appliance to a Recovery Platform
Protection storage offers an end-to-end solution, integrating full-function data protection capabilities with deduplicated storage. The simplicity and efficiency of application-centric data protection combined with the scale and performance of capacity-optimized storage systems stands to fundamentally alter the traditional backup market. Changed data is copied directly between the source and the target, without intervening backup servers. Cloud storage may also be used as a cost-effective target. Leveraging integrated software and hardware for what each does best allows vendors to offer innovations to customers in a manner that lowers their total cost of ownership. Innovations like automatic configuration, dynamic optimization, and using preferred management interfaces (e.g., virtualization consoles, pod managers) build on the proven practices of the past to integrate data protection into the customer’s information infrastructure.
No one wants to be locked into products because they are too painful to switch out; it’s time that products are “sticky” because they offer compelling solutions. IDC projects that the worldwide purpose-built backup appliance (PBBA) market will grow 16.6% from $1.7 billion in 2010 to $3.6 billion by 2015. The industry is rapidly adopting PBBAs to overcome the data protection challenges associated with data growth. Looking forward, storage systems will be expected to incorporate a recovery platform, supporting security and compliance obligations, and data protection solutions will become information brokers for what is stored on disk.
 No Comments » |
No Comments » |  Uncategorized |
Uncategorized |  Permalink
Permalink
 Posted by Gene Nagle
Posted by Gene Nagle
 The overall success of and general acceptance of server virtualization as a way to make servers more fully utilized and agile, have encouraged IT managers to pursue virtualization of the other two major data center functions, storage and networking. And most recently, the addition of external resources such as the public Cloud to what the IT organization must manage has encouraged taking these trends a step further. Many in the industry believe that the full software definition of all IT infrastructure, that is a software defined data center (SDDC), should be the end goal, to make all resources capable of fast adaptation to business needs and for the holy grail of open-API-based, application-aware, single-pane-of-glass management.
The overall success of and general acceptance of server virtualization as a way to make servers more fully utilized and agile, have encouraged IT managers to pursue virtualization of the other two major data center functions, storage and networking. And most recently, the addition of external resources such as the public Cloud to what the IT organization must manage has encouraged taking these trends a step further. Many in the industry believe that the full software definition of all IT infrastructure, that is a software defined data center (SDDC), should be the end goal, to make all resources capable of fast adaptation to business needs and for the holy grail of open-API-based, application-aware, single-pane-of-glass management.





